Spark on Kubernetes tại Fossil 🤔
Tại Fossil, có hàng trăm triệu log records được thu thập mỗi ngày, được xử lý và lưu trữ trong các Data Warehouse bởi hệ thống Fossil Data Platform. Data Platform là một hệ thống event-driven được thiết kế dựa trên Lambda Architecture gồm một near-realtime layer và một batch layer. Near-realtime layer cho phép data từ lúc đẩy vào hệ thống cho đến khi xuất hiện ở đầu cuối có độ trễ tối đa 15 phút. Batch layer sẽ tính toán bộ data lại một lần nữa, vào cuối mỗi ngày, để đảm bảo data được chính xác và tối ưu hóa để lưu trữ lâu dài.
Hệ thống được triển khai trên Kubernetes Cluster bao gồm nhiều thành phần. Một số thành phần có thể kể đến như: API Ingession, CDC, Kafka Connector, các Parser và Transformer xử lý raw data. Apache Airflow và Apache Spark cũng được triển khai trên Kubernetes, quản lý bởi các Kubernetes Operators.
Apache Spark được chọn làm công nghệ cho Batch layer bởi khả năng xử lý một lượng lớn data cùng một lúc. Ở thiết kế ban đầu, team data chọn sử dụng Apache Spark trên AWS EMR do có sẵn và triển khai nhanh chóng. Dần dần, AWS EMR bộc lộ một số điểm hạn chế trên môi trường Production.
Trong bài viết này, mình sẽ nói về tại sao và làm thế nào team Data chuyển từ Spark trên AWS EMR sang Kubernetes.
1. Apache Spark trên AWS EMR
Trong thế giới của Data Engineering thì Apache Spark không còn quá xa lạ. Spark là open source với mục đích triển khai một hệ thống tính toán in-memory và massively parallel. Spark được sử dụng rộng rãi trong nhiều lĩnh vực xử lý Big Data, từ Data Analytics đến Machine Learning. Spark được thiết kế để có thể chạy ở Standalone Mode cũng như trên Mesos, YARN và Kubernetes.
Ở thiết kế đầu tiên, team Fossil Data Platform thiết kế sử dụng Apache Spark để chạy các Jobs cùng với Apache Hive trên AWS EMR. Điều này hết sức đơn giản do việc thiết lập cụm AWS EMR khá dễ dàng và nhanh chóng. Dần dần sau một khoảng thời gian, team nhận ra có một số điểm yếu:
- Tại thời điểm đó AWS chưa ra mắt EMR Serverless và EMR on EKS, việc scale thêm EC2 Node tốn thời gian do phải bootstrap (cài đặt và khởi động) 1 loạt các services cần thiết.
- Trên mỗi Node sẽ tốn 1 phần resources overhead để chạy các services đó (Spark, Livy, Zeppelin, Hive, HDFS, Monitoring, …).
- Chi phí quản lý EMR Cluster.
- HA trên EMR bắt buộc bạn phải có 3 node master chạy song song, nếu 1 node master chết thì node khác lên thay, nhưng bình thường sẽ lãng phí 2 node backup không làm gì cả.
- ...
Trong khi toàn bộ hệ thống Data Platform được thiết kế dưới dạng micro-services và event-driven architecture với nhiều thành phần chạy trên Kubernetes, team bắt đầu nghĩ đến việc deploy Spark Jobs trên Kubernetes thay vì EMR, có một số ưu điểm có thể kể đến:
- Tiết kiệm chi phí, bao gồm chi phí cho việc đợi provisioning và bootstrapping phức tạp, costing được tính theo giây, việc này cũng giúp loại bỏ chi phí quản lý EMR cluster, khoảng $700-$800 cho một tháng (chưa bao gồm chi phí EC2).
- Spark trên YARN cũng tốn chi phí maintenance không nhỏ.
- Tiết kiệm chi phí do không phải duy trì một lúc 3 Node Master HA.
- Không thể chạy nhiều version của Spark khác nhau, ví dụ đang sử dụng Spark 2.4.x, bạn cần upgrade một số Application lên Spark 3.x để dùng tính năng mới, bắt buộc phải upgrade các Application cũ hoặc cài đặt một Cluster EMR mới. Ngược lại Spark trên Kubernetes cho phép chạy các driver, executer trên các Kubernetes Pod, mỗi Pod gồm 1 container nên có thể isolated workloads dễ dàng. Ngoài ra có thể thừa hưởng được mọi tính năng của Kubernetes như:
- Request/Limit: điều chỉnh hay giới hạn resources (mem, cpu), số lượng Pod cho mỗi Spark Application.
- Namespace: Kubernetes Namespace còn cho phép phân quyền cho các team, các môi trường với lượng resources xác định nữa (e.g. namespace:
data-prod,data-stag,data-dev, …) - Tận dụng được Kubernetes Autoscaler và có khả năng scale-to-zero.
- Node Selector và Affinity: cho phép chọn loại Node tùy theo tính chất của Jobs đó, ví dụ một số Jobs cần nhiều Mem, trong khi một khố Jobs khác cần nhiều CPU.
2. Spark on Kubernetes - Livy
Kể từ 2.3.x là Spark đã hỗ trợ chạy trên cluster quản lý bởi Kubernetes. Chúng ta có thể submit một Spark Application bất kỳ trực tiếp bằng cách sử dụng spark-submit trên comand line, chỉ cần thay --master đến địa chỉ của Kubernetes k8s://<api_server_host>:<k8s-apiserver-port>
Ví dụ để chạy Spark Pi trên Cluster mode, hãy xem ví dụ sau:
$ bin/spark-submit \
--master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=<spark-image> \
local:///path/to/examples.jar
Chú ý là k8s://https:// mình không viết nhầm đâu nhé.
Nhu cầu để có thể submit một loạt jobs hàng ngày, team sử dụng Apache Livy trên Kubernetes, với kiến trúc như dưới đây:
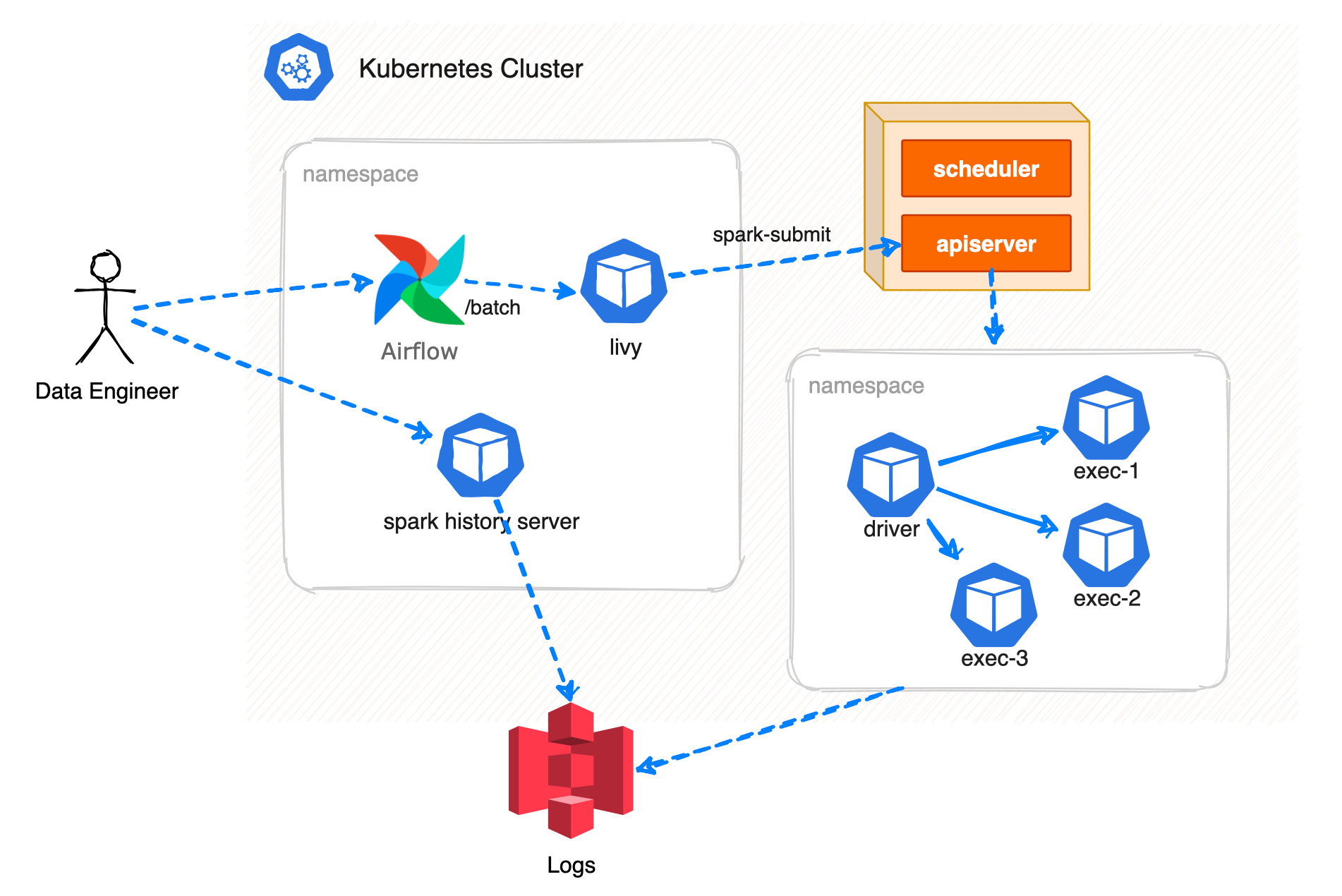
Team sử dụng Livy, đây là một service cho phép tương tác với Spark Cluster thông qua RESTful API. Livy đã từng được sử dụng trên EMR, ở Kubernetes chỉ cần deploy Livy thông qua Helm một cách dễ dàng. Xem thêm cách cài đặt Livy ở đây. Để trigger Livy có nhiều cách, team sử dụng Airflow như là một scheduler, có nhiều loại DAGs tùy vào tính chất của mỗi Jobs, các DAG sẽ trigger Livy, theo dõi trạng thái của Jobs đó cũng thông qua API, retry hoặc alert khi cần thiết. DAG cũng có nhiệm vụ kiểm tra dữ liệu (data validation) kết quả đầu ra (output) cho mỗi jobs.
Tuy nhiên lại có một số điểm hạn chế như do delay từ Airflow Scheduler, Livy cũng dễ bị stuck. Nếu một jobs chạy lâu nhưng Livy bị restart thì Jobs đó cũng bị ảnh hưởng theo. Team quyết định nâng cấp.
3. Spark on Kubernetes - Spark Operator
Sau khi đánh giá khả năng của Spark Operator bởi GCP Google, team quyết định đi đến phiên bản 2.0 của architecture. Các thành phần sẽ như hình dưới đây:
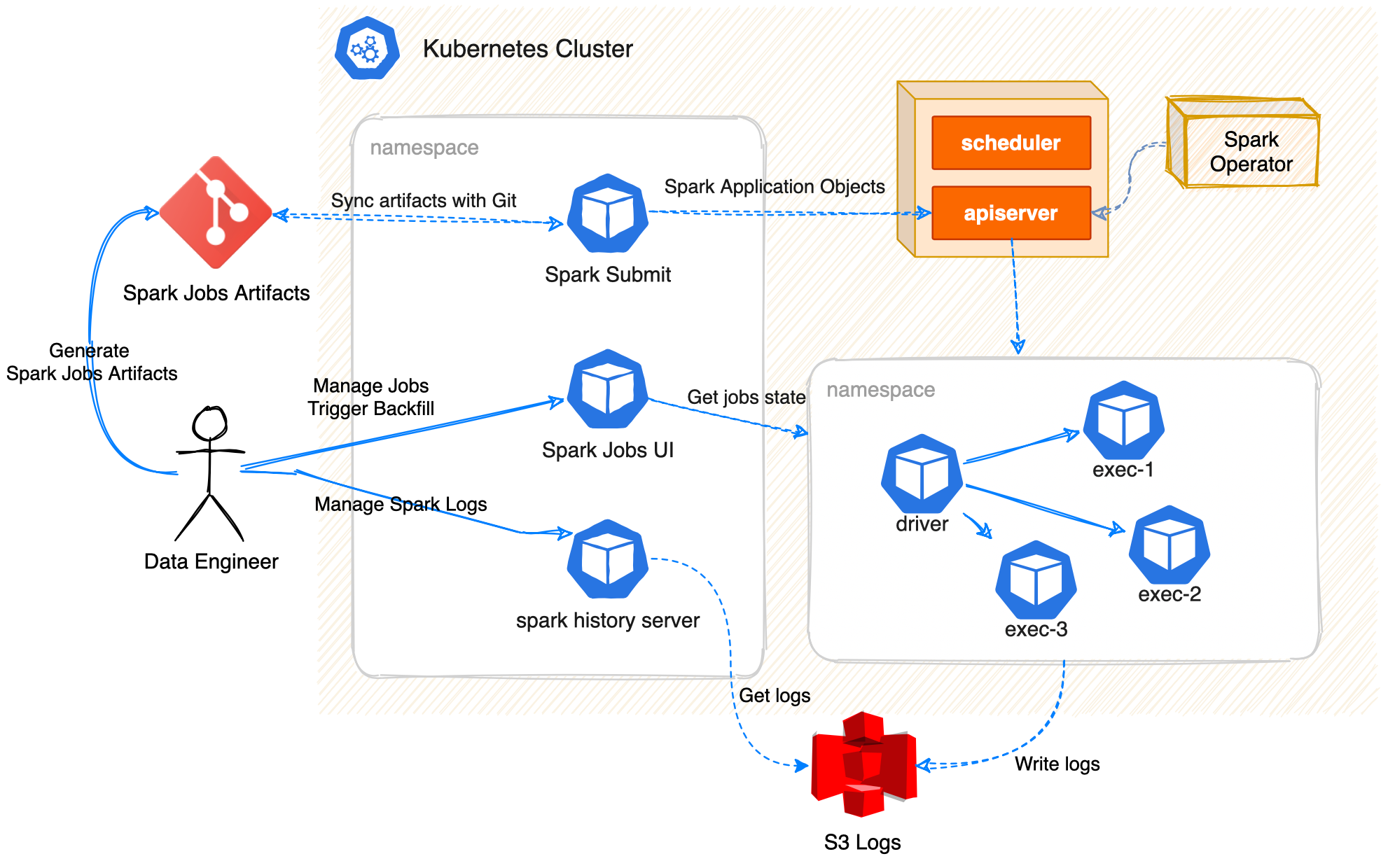
Ở kiến trúc trên, vai trò của Data Engineer sẽ là:
- (1) generate ra Spark Jobs Artifacts và commit/push vào một Repo trên Git. Spark Jobs Artifacts sẽ có dạng như ví dụ này, có thể hiểu đây là một specs để Spark Operator có thể submit và quản lý Jobs trên namespace của mình. Có 2 loại CRDs của Spark Operator sinh ra để quản lý là
SparkApplicationvàScheduledSparkApplication. - (2) Spark Submit Worker là một Pod chạy trên Kubernetes, có nhiệm vụ đọc/sync những gì trên Git và apply vào Kubernetes thông qua Kubernetes API (hoạt động giống như
kubectl apply -f). - (3) Spark Operator như mọi Operator khác, sẽ lắng nghe/đọc CRDs được submit vào cluster, sẽ specify, running, và cập nhật status của các Spark application. Từ một
SparkApplicationSpark Operator sẽ dựng một POD driver, POD driver sẽ request thêm từ Kubernetes để dựng thêm các POD executor, đến khi nào Spark Jobs thực hiện xong sẽ tự động terminate các pod này. Logs sẽ được lưu giữ ở S3 bucket. - (4) Spark History Server sẽ render logs từ S3 bucket, giúp team engineer dễ dàng hơn trong việc traceback lại các jobs cũ đã finish.
- (5) Spark Jobs UI là một Web UI để quản lý tất cả các Spark Jobs trên Git, kiểm tra trạng thái của mỗi Jobs trên Cluster, monitor, data validation cũng như backfill.
Hãy tìm hiểu xem một số thành phần chính đóng vai trò gì nhé.
3.1. Spark Operator
Spark Operator là một Kubernetes Operator được thiết kế cho Spark nhằm mục đích xác định và thực thi các Spark applications dễ dàng như các workloads khác trên Kubernetes, bằng cách sử dụng và quản lý một Kubernetes custom resources (CRD) để specifying, running, và update status của Spark applications.
Để tìm hiểu thêm bạn có thể xem qua về Design, API Specification, và User Guide trên Github.
Ví dụ để cài đặt Spark Operator trên namespace spark-jobs thông qua Helm chart, ở đây mình bật tính năng webhook. Tùy vào hệ thống quản lý của bạn mà có thể cài đặt thông quan FluxCD hay ArgoCD, ở đây mình sử dụng helm cli đơn giản cho việc minh họa:
helm repo add spark-operator https://googlecloudplatform.github.io/spark-on-k8s-operator
helm install spark-operator \
spark-operator/spark-operator \
--namespace spark-jobs \
--set sparkJobNamespace=spark-jobs \
--set webhook.enable=true
3.2. Spark Submit Worker
Một SparkApplication có về cơ bản là một resource CRD, có thể được apply vào cluster bằng kubectl, như ví dụ dưới đây:
# spark-pi.yaml
---
apiVersion: 'sparkoperator.k8s.io/v1beta2'
kind: SparkApplication
metadata:
name: pyspark-pi
namespace: spark-jobs
spec:
type: Python
pythonVersion: '3'
mode: cluster
image: 'gcr.io/spark-operator/spark-py:v3.1.1'
imagePullPolicy: Always
mainApplicationFile: local:///opt/spark/examples/src/main/python/pi.py
sparkVersion: '3.1.1'
restartPolicy:
type: OnFailure
onFailureRetries: 3
onFailureRetryInterval: 10
onSubmissionFailureRetries: 5
onSubmissionFailureRetryInterval: 20
driver:
cores: 1
coreLimit: '1200m'
memory: '512m'
labels:
version: 3.1.1
serviceAccount: spark
executor:
cores: 1
instances: 1
memory: '512m'
labels:
version: 3.1.1
Để submit SparkPi này vào Kubernetes, bạn chỉ cần sử dụng:
kubectl apply -f spark-pi.yaml
kubectl get sparkapp
Để tự động hóa, Spark Submit Worker là một Cronjob Pod để định kỳ (~5ph) sync với Git Repo và apply mọi spark app dưới dạng các file YAML và mọi thay đổi lên cluster. Có 2 dạng artifacts mà Spark Submit quản lý là SparkApplication và ScheduledSparkApplication như đã nói ở trên.
Việc quản lý các Spark Application dưới dạng YAML specs còn giúp có thêm một số lợi ích của GitOps: mọi thay đổi đều được Git Versioning, phân quyền trên Git, review thay đổi, approve hoặc reject thay đổi, dễ dàng rollback bằng cách revert git, …
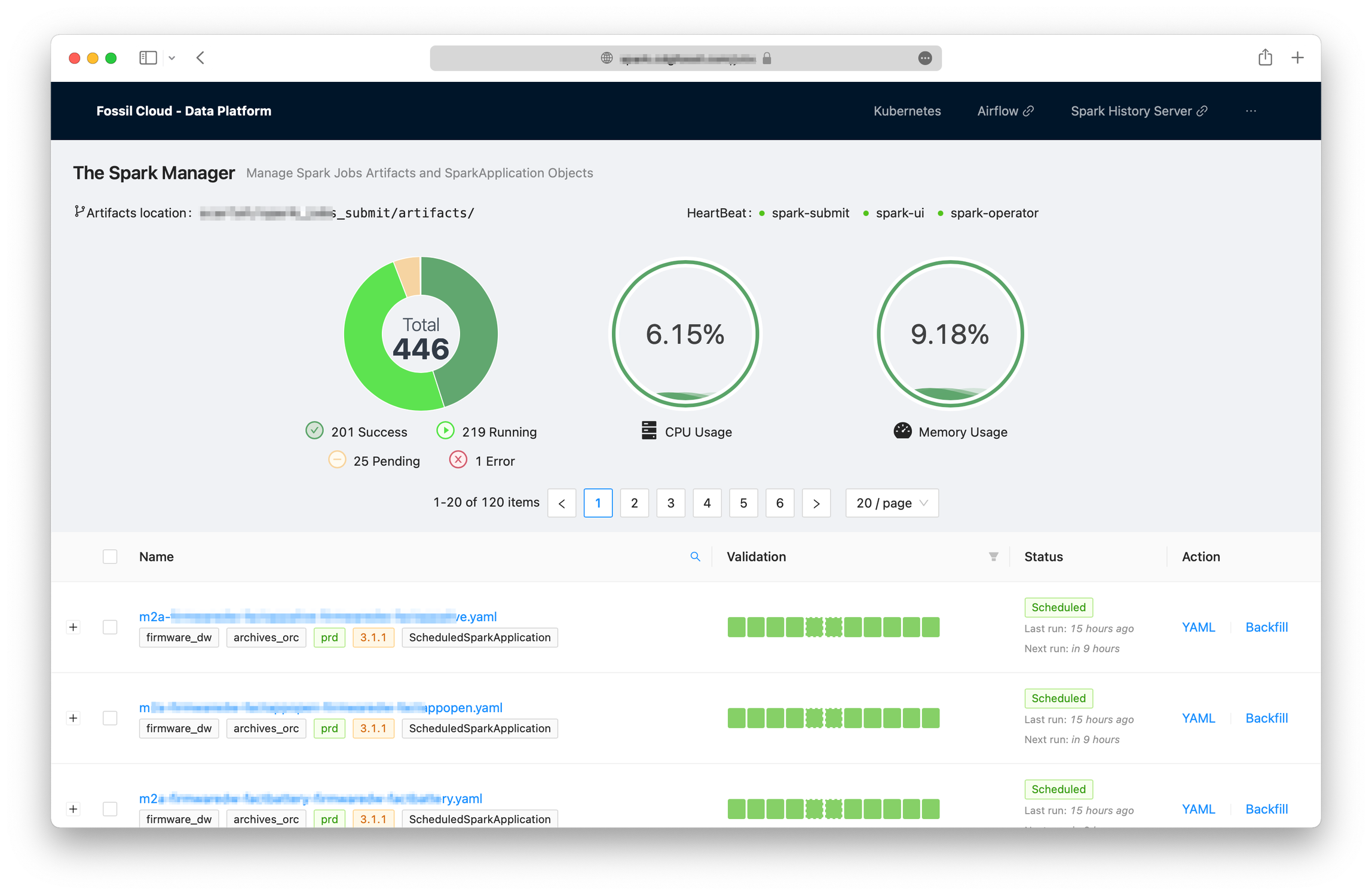
3.3. Spark Jobs UI
Spark Jobs UI hay Spark Jobs Dashboard là một Web UI để quản lý Spark Jobs và artifacts được generated hoặc customized bởi engineers. Dashboard được viết bằng Typescript và Next.js, gồm một số tính năng cơ bản như:
- Liệt kê mọi Spark Jobs artifacts
- Xem nội dung của từng Spark Application YAML files
- Xem thông tin status của mỗi Scheduled Spark Application như là
scheduleStatus,lastRun,nextRun, ... - Kiểm tra nhanh dữ liệu output (basic data validation) cho mỗi jobs theo interval của Jobs đó. Ví dụ một jobs theo ngày (daily), UI sẽ kiểm tra mỗi ngày xem có data của ngày hôm đó có hợp lệ không.
- Thống kê cơ bản như số Jobs đang chạy, đang pending, số lượng Jobs lỗi, resources (CPU/Memory) sử dụng, …
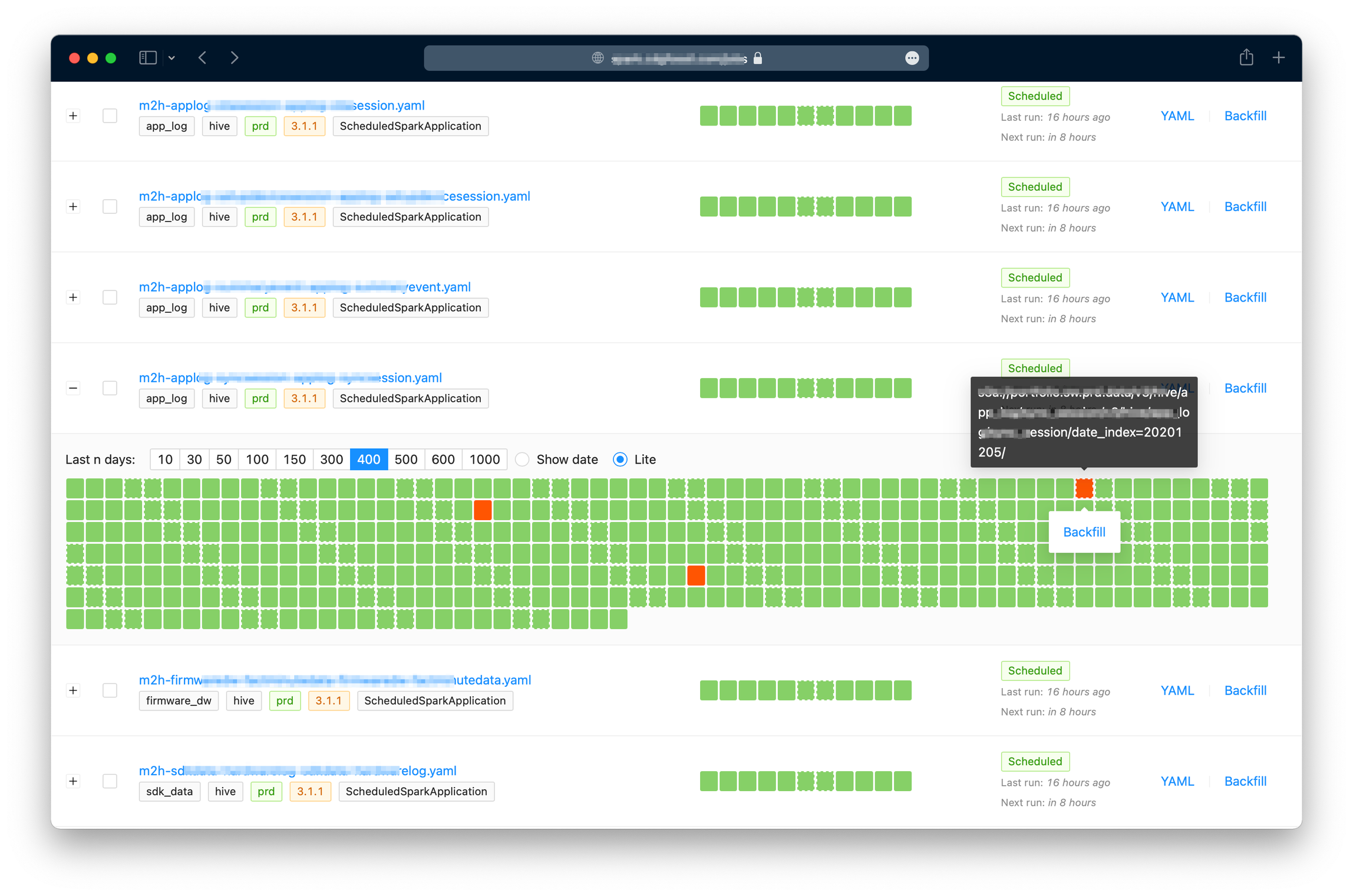
- Backfill: có thể trigger chạy lại cho một hoặc nhiều jobs, một ngày hoặc nhiều ngày.
Hãy xem một số screenshot dưới đây để có cái hình cụ thể hơn:
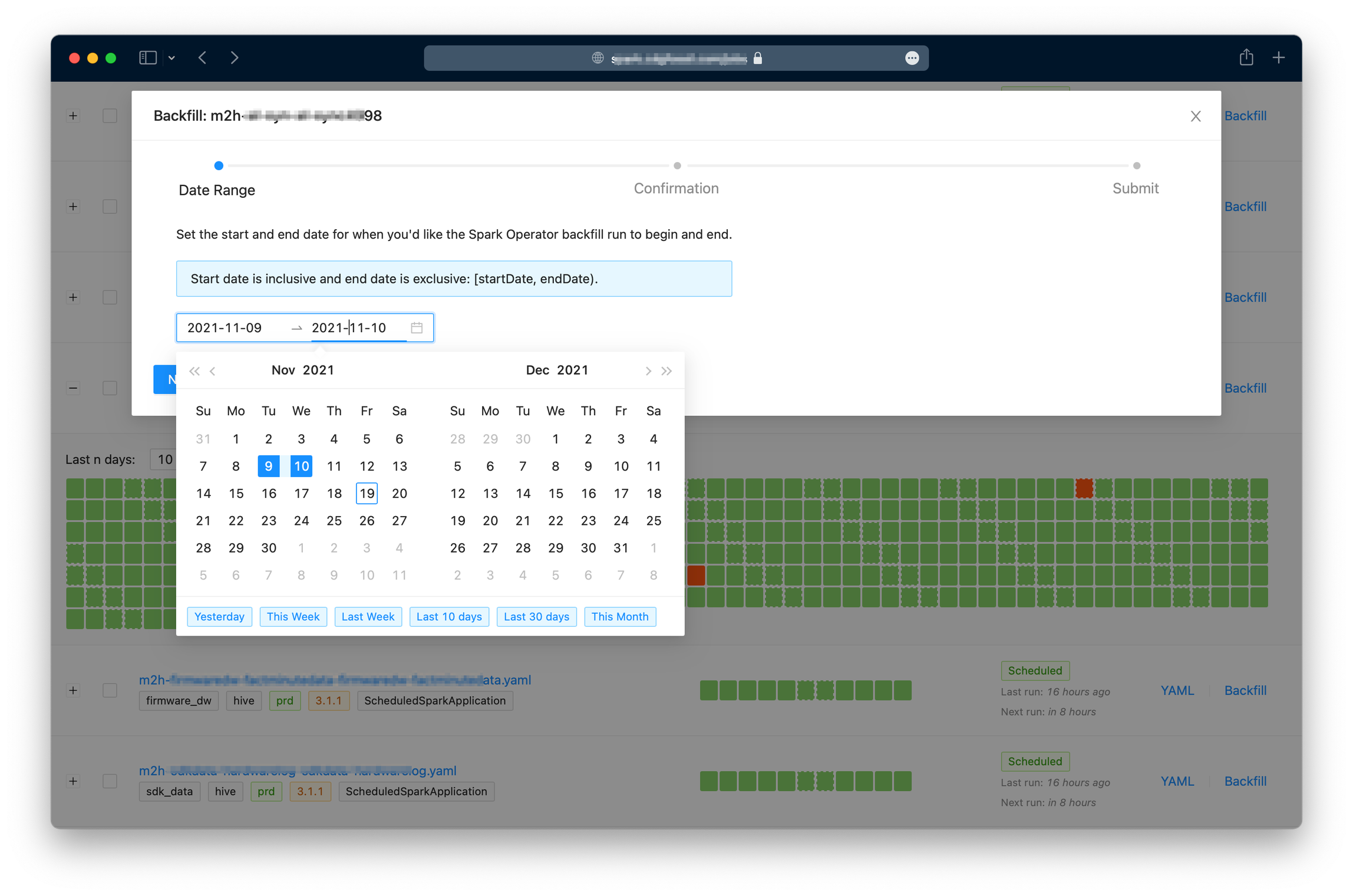
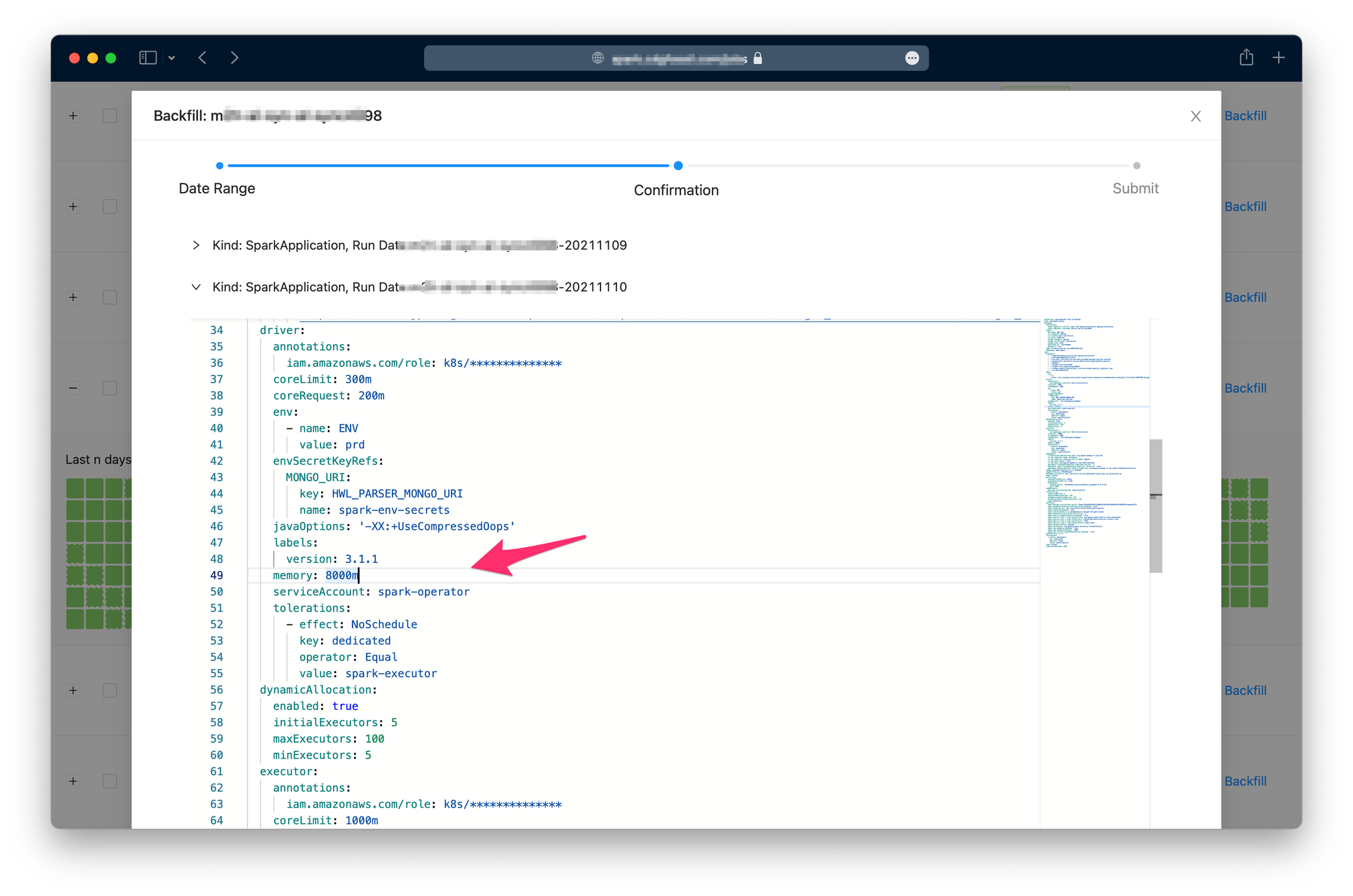
3.4. Spark History Server
Spark History Server là một Spark Web UI có sẵn của Spark, dùng để monitor trạng thái và tài nguyên sử dụng cho Spark App. Spark History Server được dựng lên để đọc lại logs của các Jobs đã hoàn thành trước đó lưu trên S3 bucket. Mỗi SparkApplication sẽ được config để push Spark events lên S3:
spec:
sparkConf:
'spark.eventLog.enabled': 'true'
'spark.eventLog.dir': 's3a://fossil-spark/logs/'
Spark History Server cũng có thể được cài đặt thông qua this Helm Chart, chỉ cần trỏ đúng đường dẫn của logDirectory vào đúng vị trí S3 bucket mà Spark đã gửi lên.
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm install stable/spark-history-server \
--namespace spark-jobs \
--set enableS3=true \
--set logDirectory=s3a://fossil-spark/logs/
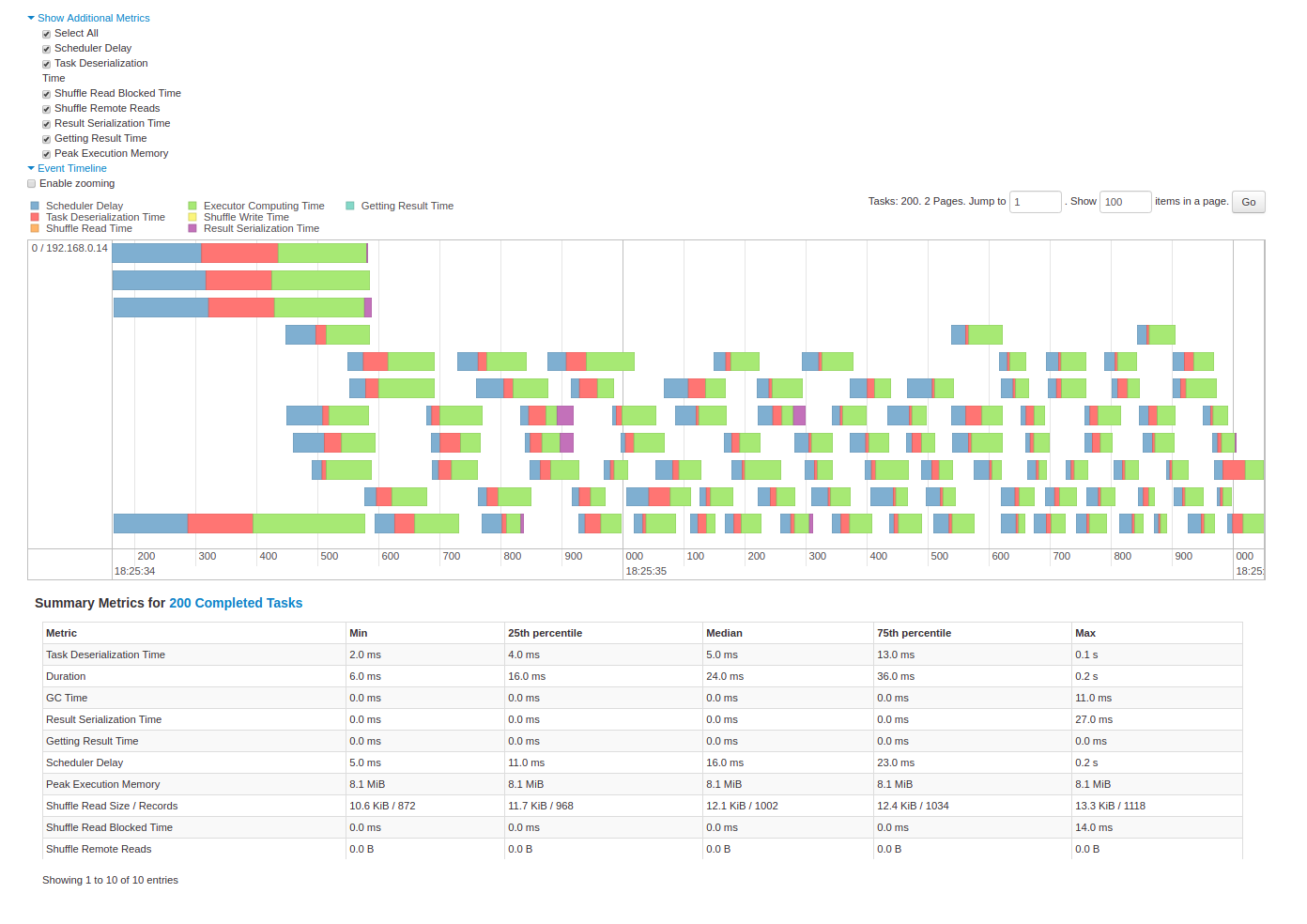
4. Performance Tuning on Kubernetes
Có rất nhiều tối ưu được được thực hiện do tính chất Spark trên Kubernetes + AWS sẽ có chút khác biệt với Spark trên YARN. Một số có thể kể đến mà bạn có thể xem thêm ở đây Spark on Kubernetes Performance Tuning hoặc dễ dàng tìm kiếm trên Google:
- Using Volcano Scheduler for Gang schedule
- Using Kryo serialization
- Ignoring Data Locality because of S3 data source.
- I/O for S3
- Tuning Java
- Enabled Dynamic Allocation and Dynamic Allocation Shuffle File Tracking
- Using Kubernetes Node Spot instance for the executors.
5. Kết
Như vậy là mọi người đã có thể hình dung được cách mà team Data Platform tại Fossil sử dụng vận hành Apache Spark trên Kubernetes.
Do có nhiều chi tiết, nhiều vấn đề kỹ thuật, cách cài đặt, cách tối ưu, … mà mình khó có thể đề cập hết được, do đó bài viết chỉ dừng lại ở tính chất giới thiệu tổng quát. Mình sẽ cố gắng chi tiết hóa các vấn đề ở các bài viết khác nếu có thể trong tương lai.