Spark Performance tuning is a process to improve the performance of the Spark, on this post, I will focus on Spark that runing of Kubernetes.

Spark Performance tuning is a process to improve the performance of the Spark, on this post, I will focus on Spark that runing of Kubernetes.
Chú trọng vào việc đơn giản hóa và rõ ràng cách viết Airflow DAG, cách trao đổi thông tin giữa các tasks, Airflow 2.0 ra mắt Taskflow API cho phép viết đơn giản và gọn gàng hơn so với cách truyền thống, đặc biệt vào các pipelines sử dụng PythonOperators.

Spark đã quá nổi tiếng trong thế giới Data Engineering và Bigdata. Kubernetes cũng ngày càng phổ biến tương tự, là một hệ thống quản lý deployment và scaling application. Bài viết này bàn đến một số lợi ích khi triển khai ứng dụng Apache Spark trên hệ thống Kubernetes.

To schedule a Python script or Python function in Airflow, we use `PythonOperator`.

The problem with running Spark on Kubernetes is the logs go away once the job completes. Spark has tool called the Spark History Server that provides a UI for your past Spark jobs. In this post, I will show you how to use Spark History Server on Kubernetes.
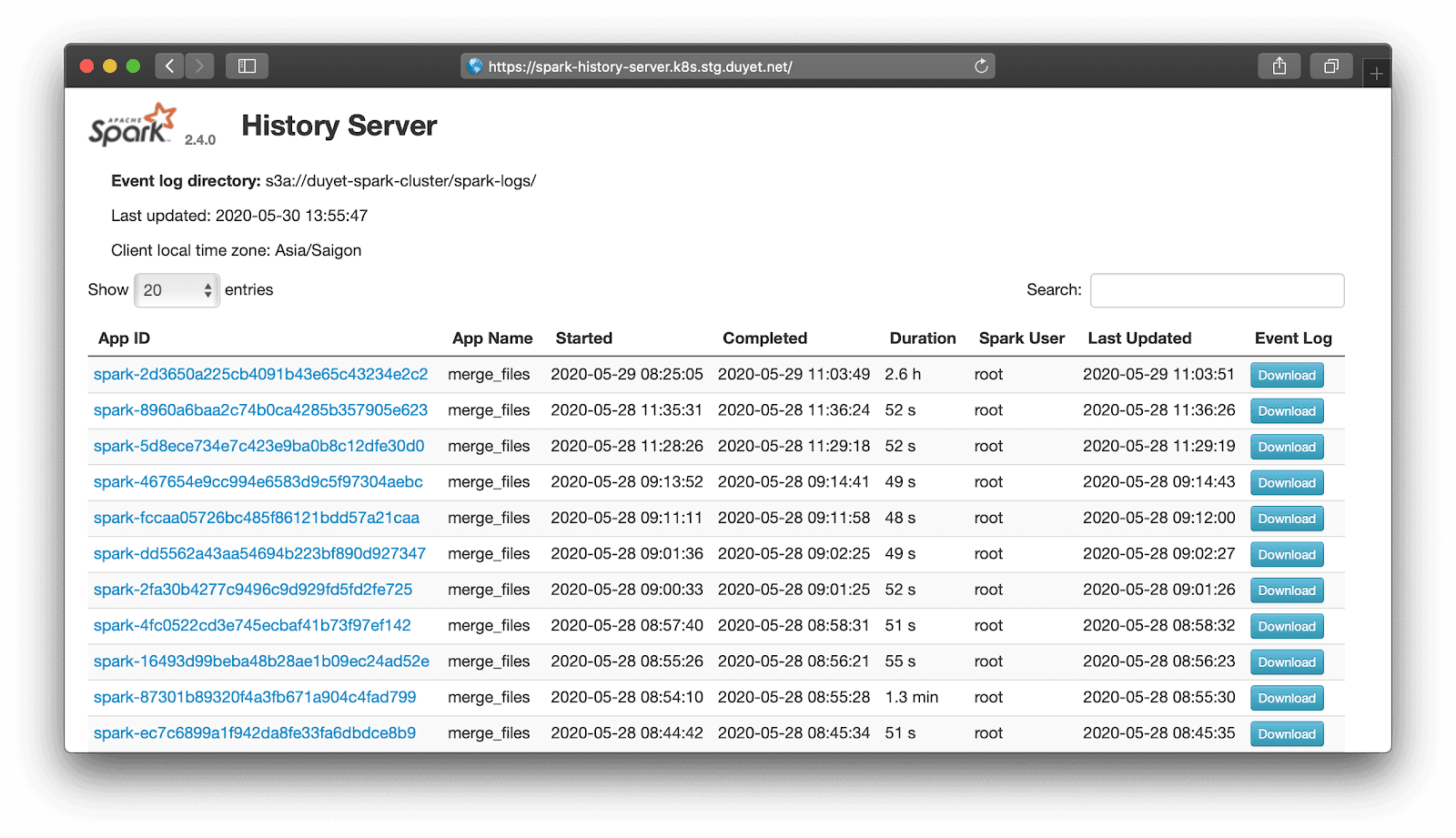
Spark can run on clusters managed by Kubernetes. This feature makes use of native Kubernetes scheduler that has been added to Spark.
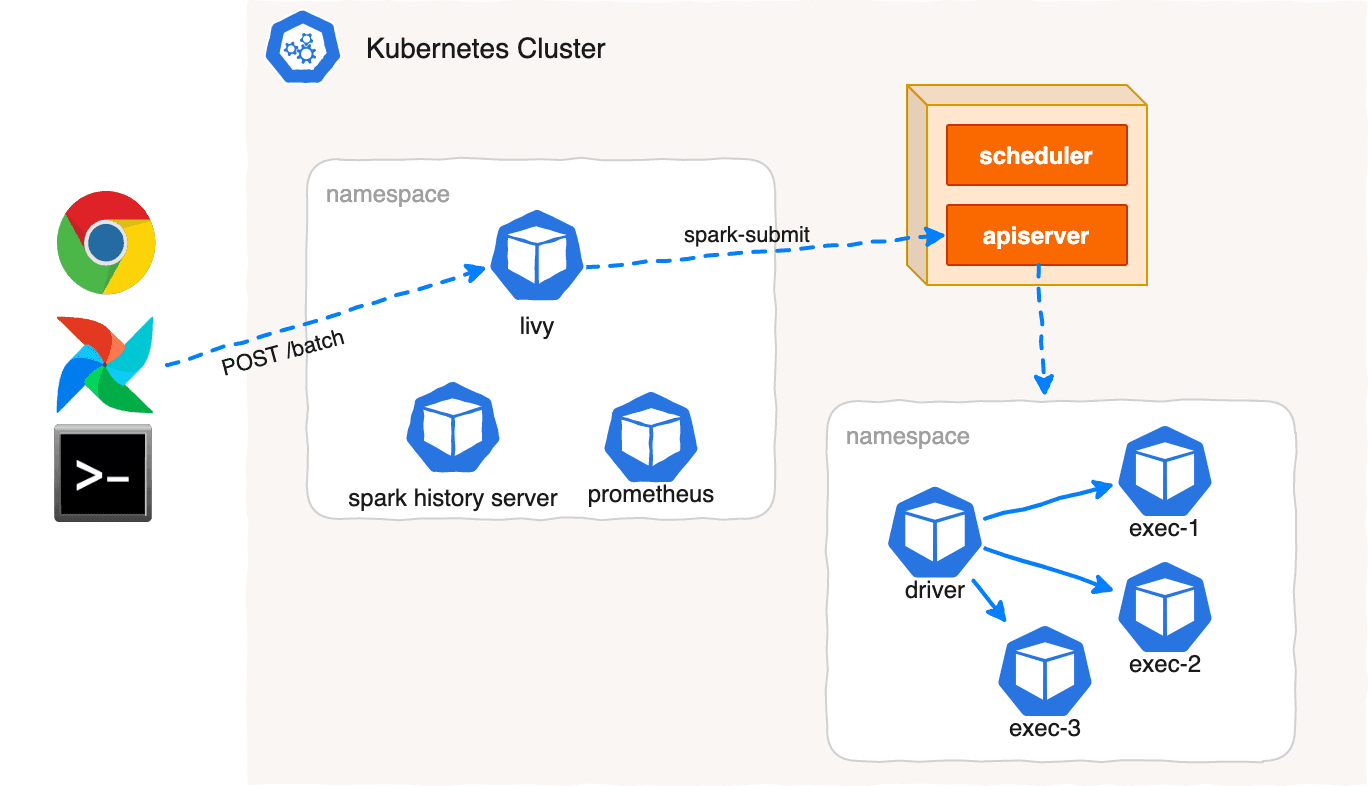
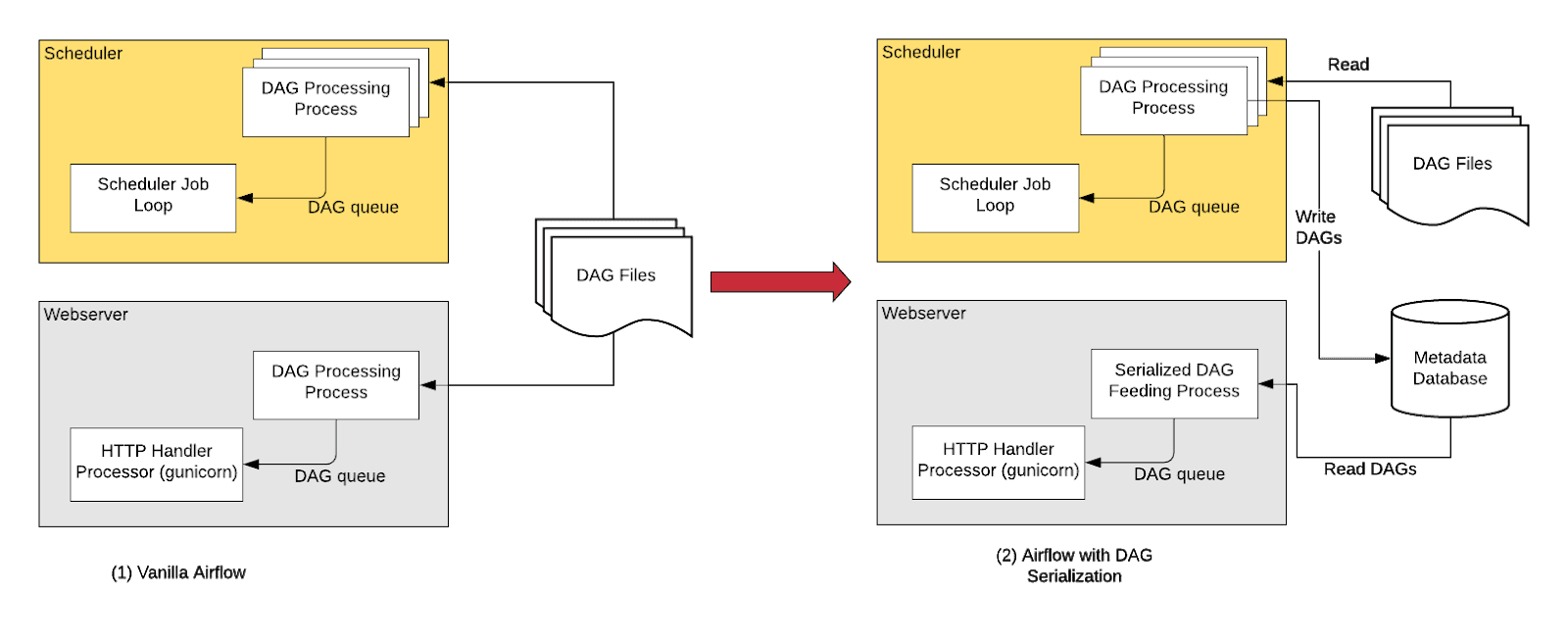
In order to make Airflow Webserver stateless, Airflow >=1.10.7 supports DAG Serialization and DB Persistence.
Normally, with BigQuery as a data source of Data Studio, users (of Data Studio Dashboard) might end up generating a lot of queries on your behalf — and that means you can end up with a huge BigQuery bill. It’s taken so long to refresh data when you change something in development mode. How to solve this problem with Spreadsheet, for free?

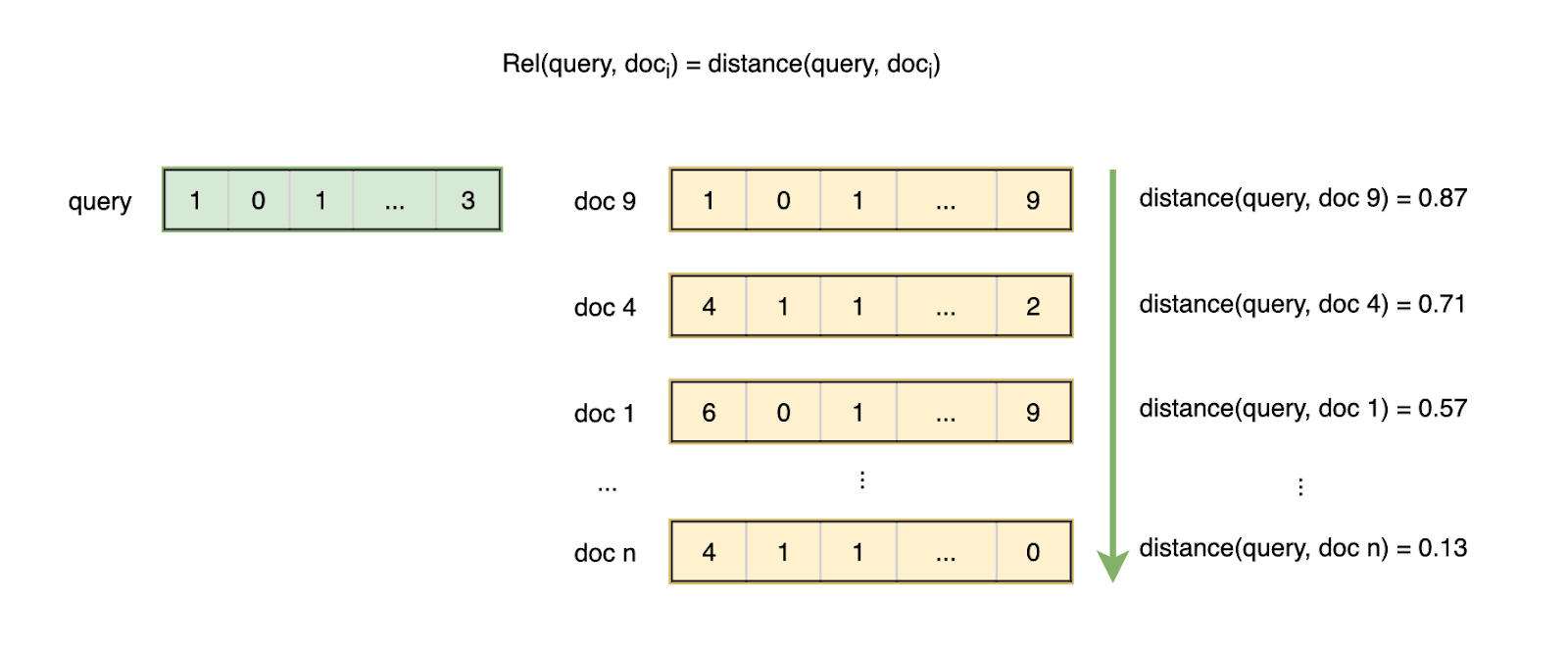
Tiếp theo về các chỉ số đánh giá các hệ thống Information Retrieval, bài này sẽ bàn về đánh giá hệ thống tìm kiếm với Ground truth là non-binary (không phải nhị phân), và đánh giá hệ thống large scale.
Ghi lại mấy cuốn sách hay (Engineering) đã đọc qua.

Trong bài này chúng ta sẽ tìm hiểu về cách đánh giá các hệ thống Information Retrieval, thách thức của việc đánh giá và các độ đo phổ biến như Precision/Accuracy, Recall, R-precision, F-measure, MAP, ...

Hệ thống tra cứu thông tin - Information Retrieval. Một hệ thống tìm kiếm thông tin (Information Retrieval - IR) là một hệ thống tra cứu (thường là các tài liệu văn bản) từ một nguồn không có cấu trúc tự nhiên (thường là văn bản), chứa đựng một số thông tin nào đó từ một tập hợp lớn. Một trong những kỹ thuật phổ biến trong Information Retrieval đó là Vector Space Model.
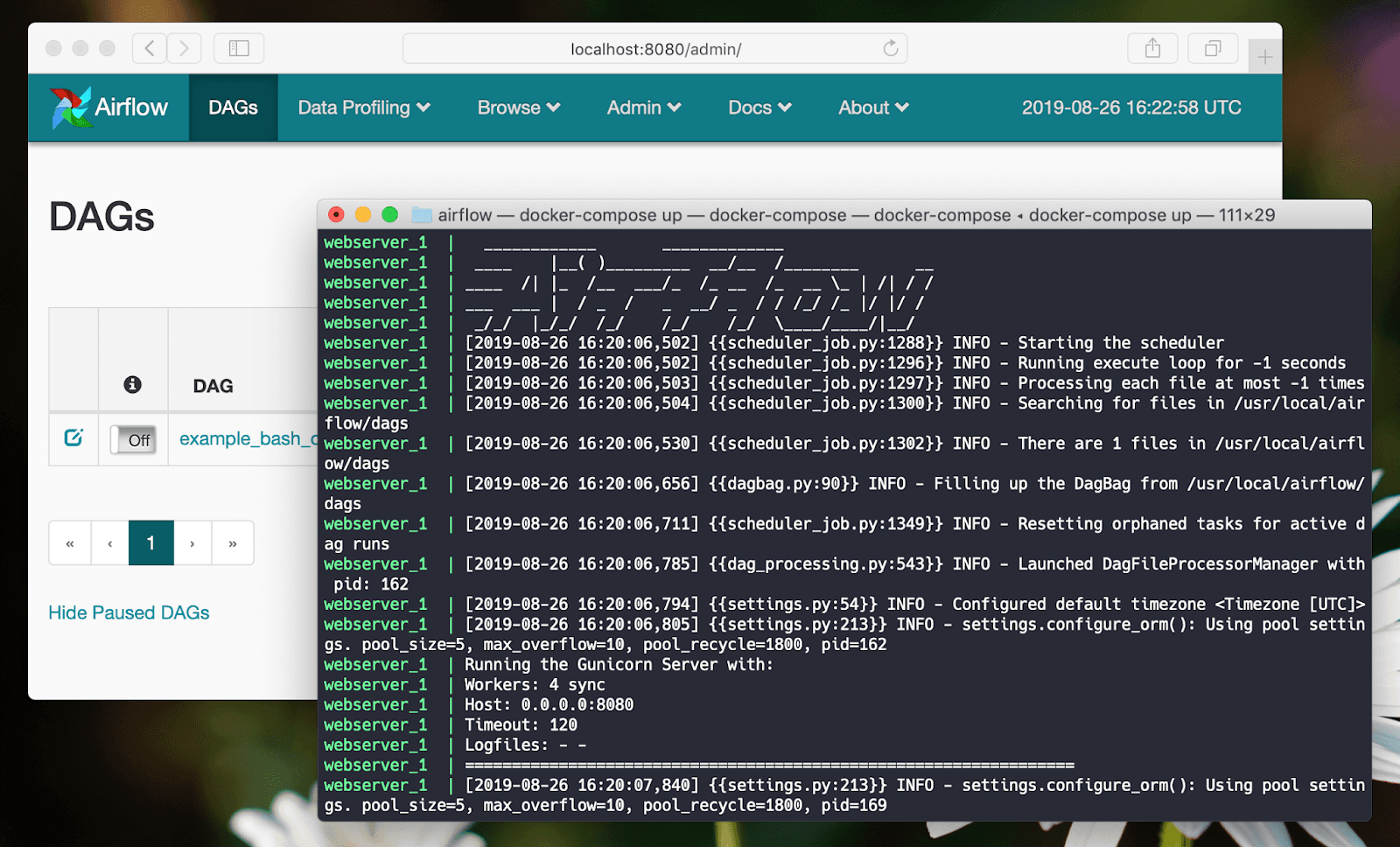
Một số ghi chép, tips & tricks của mình trong quá trình sử dụng Apache Airflow.

Trong bài này mình sẽ hướng dẫn cách thiết lập môi trường develop Apache Airflow dưới local bằng Docker Compose.
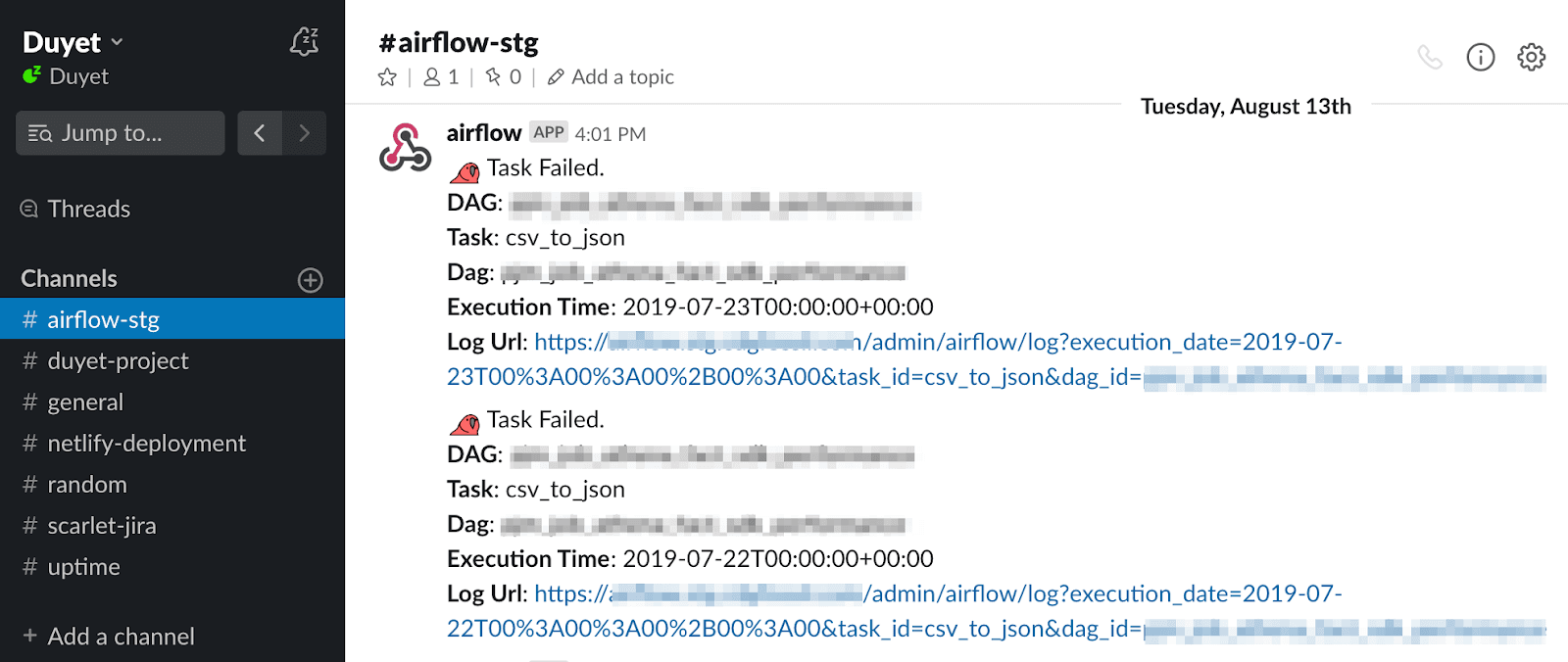
Slack là một công cụ khá phổ biến trong các Team, slack giúp tập hợp mọi thông tin về Slack (như Jira alert, ETL pipelines, CI/CD status, deployments, ...) một cách thống nhất và dễ dàng theo dõi. Bài viết này mình hướng dẫn gửi mọi báo lỗi của Airflow đến Slack.
Biến `context` trong airflow là biến hay sử dụng trong Airflow (`PythonOperator` with a callable function), nhưng mình rất hay quên, note lại đây để dễ dàng tra cứu.

Mình vừa có một chút chia sẻ ngắn về xây dựng Data Pipeline trên AWS, phục vụ cho ETL và Data Aggregation.
![[Slide] Build simple data pipeline for ETL and data aggregation on AWS](/_next/image?url=https%3A%2F%2F1.bp.blogspot.com%2F-bubYERdAr50%2FW-kXVP6JKfI%2FAAAAAAAA1Ic%2FnvICF9mhxEMxkpqhySrjxllUfuAdu2nZQCLcBGAs%2Fs1600%2FScreen%252BShot%252B2018-11-12%252Bat%252B1.01.31%252BPM.png&w=1920&q=75)
Trong blog này mình sẽ custom lại vn.vitk để có thể chạy như một thư viện lập trình, sử dụng ngôn ngữ python (trên PySpark và Jupyter Notebook).
Jupyter Notebook là công cụ khá mạnh của lập trình viên Python và Data Science. Nếu dùng R, Jupyter cũng cho phép ta tích hợp R kernel vào Notebook một cách dễ dàng.
Lưu trữ dữ liệu dưới dạng Columnar như Apache Parquet góp phần tăng hiệu năng truy xuất trên Spark lên rất nhiều lần. Bởi vì nó có thể tính toán và chỉ lấy ra 1 phần dữ liệu cần thiết (như 1 vài cột trên CSV), mà không cần phải đụng tới các phần khác của data row. Ngoài ra Parquet còn hỗ trợ flexible compression do đó tiết kiệm được rất nhiều không gian HDFS.
Map-Reduce là một giải pháp! Map-Reduce được phát minh bởi các kỹ sư Google để giải quyết bài toán xử lý một khối lượng dữ liệu cực lớn, vượt quá khả năng xử lý của một máy tính đơn có cấu hình khủng.
Nhân dịp tuyển sinh ĐH này, mình có project về thu thập dữ liệu tuyển sinh của các thí sinh trên trang của các trường ĐH. Project này mục tiêu là thu thập toàn bộ thông tin của thí sinh (SBD, tên, tuổi, điểm các môn, nguyện vọng các ngành, trường mà thí sinh nộp xét tuyển, ...). Điều oái oăm là mỗi trường công bố dữ liệu 1 cách hết sức ... tùm lum và tào lao.
